The $50 Billion AI Healthcare Bet That's Missing the Economics
Welcome to the DHEPlab Newsletter
[

{kind=link}
Welcome to the DHEPlab Newsletter
Where economics meets digital health innovation
Welcome to the inaugural issue. If you’re here, you probably care about making digital health actually work—not just in the lab, but in healthcare systems with their layered incentives, institutional constraints, and behavioral dynamics.
That’s what we study at the Digital Health Economics & Policy Lab at UNC. This newsletter shares frameworks, evidence, and insights from the intersection of health economics and technology.
The $50 Billion AI Healthcare Bet That’s Missing the Economics
Healthcare AI companies have raised over $50 billion in the past five years.[1] Most will underperform—not because the models don’t work, but because the economics don’t.
Here’s the question that rarely gets asked: Who benefits from being right, and who pays when the AI is wrong?
The answer determines adoption more than any accuracy metric.
The Missing Layer
A typical healthcare AI development process:
Technical team: Builds sophisticated models, optimizes for accuracy
Clinical team: Reviews medical appropriateness, validates against expert judgment
Deployment: Launch and measure adoption
The missing layer connects technology to human behavior—the economic incentives, behavioral factors, and institutional dynamics that determine real-world usage.
This isn’t a niche problem. It’s the central challenge.
Sendak et al.’s 2020 review of machine learning deployment in healthcare documents this pattern: technically sophisticated AI tools achieve impressive accuracy scores, then face adoption rates below 30%.[2] At Duke Health, an accurate readmission prediction tool saw utilization decline to near-zero within months of deployment. Melnick et al. (2020) identified documentation burden—not model performance—as the primary barrier to sustained clinical AI use.[3]
The AI was accurate. The incentive structure punished its use.
Three Failure Modes
[
{kind=link}
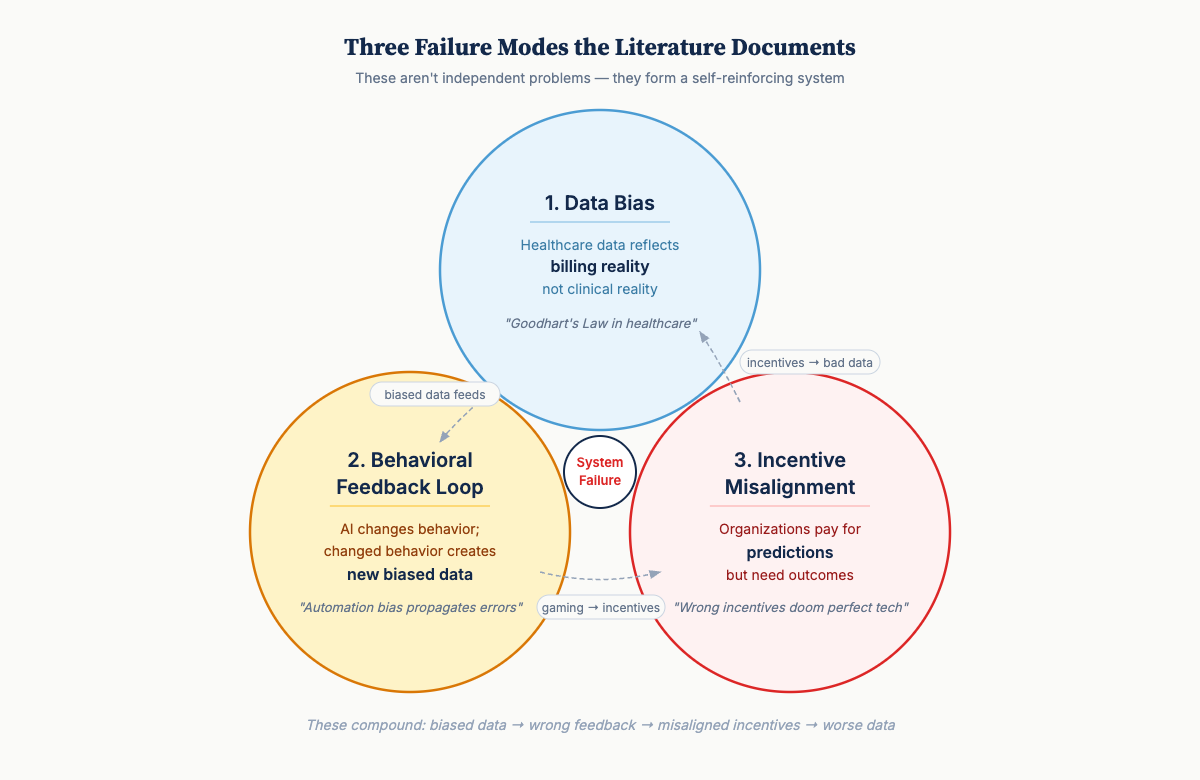
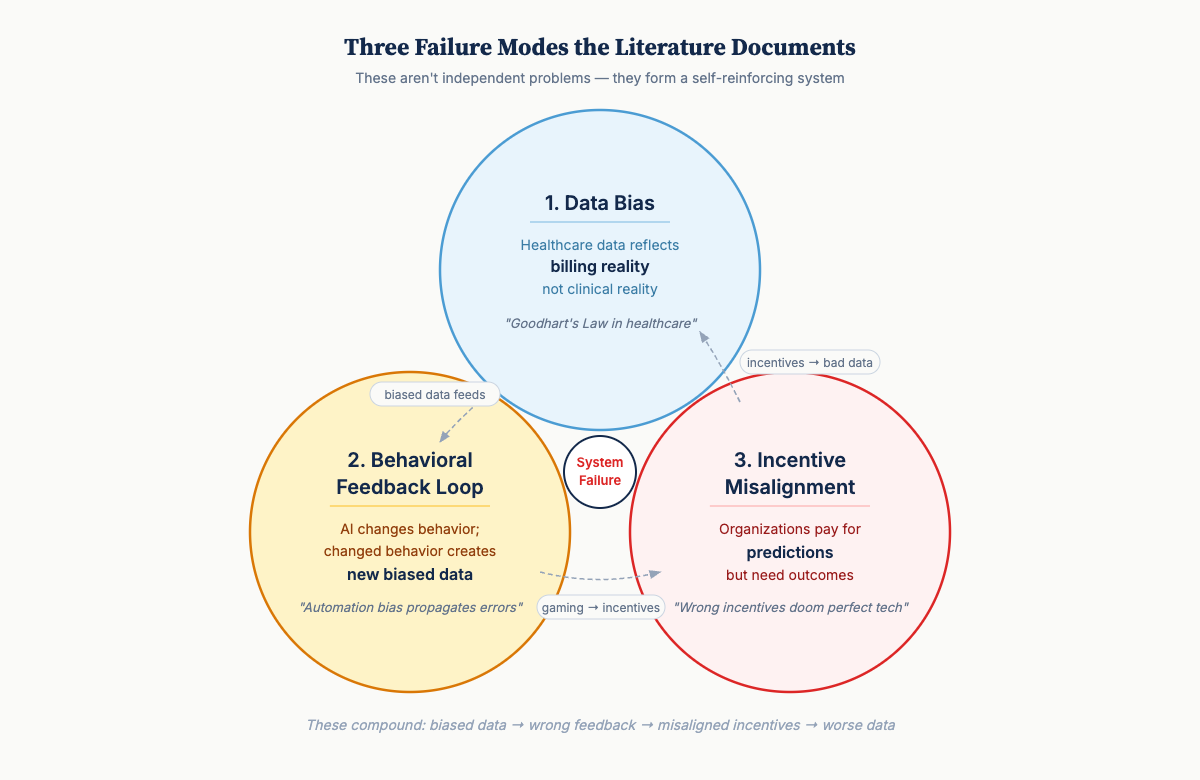
1. The Data Bias Problem
Healthcare data doesn’t reflect clinical reality—it reflects billing reality.
This isn’t a small technical problem. It’s structural. Electronic health records (EHRs) are optimized for reimbursement and liability protection, not clinical truth. Training AI on this data teaches the model strategic billing behavior rather than clinical patterns.
This is Goodhart’s Law in healthcare: When a measure becomes a target, it ceases to be a good measure.[4]
The consequences compound in low- and middle-income countries (LMICs). Who gets recorded at all depends on capacity constraints—who can afford care, which facilities have functioning systems. Achoki et al.’s 2019 analysis of Kenya’s 47 counties found health outcomes varying by a factor of three across regions, with disparities systematically worse in underserved populations.[5] The missing data aren’t missing at random.
Obermeyer et al.’s 2019 study documented this clearly: an algorithm allocating healthcare resources systematically underserved Black patients—not due to explicit bias, but because training data used healthcare costs as a proxy for health needs.[6] Patients with equal health needs but lower historical spending were deprioritized.
The bias wasn’t in the algorithm. It was in the economic structure that generated the training data.
2. The Behavioral Feedback Loop
AI doesn’t just make predictions—it changes behavior. Changed behavior creates new data that feeds back into the system.
Most AI developers underestimate this. Humans aren’t passive recipients of recommendations. We respond, adapt, and sometimes game systems.
-
Diagnostic AI recommends additional testing → Clinicians adjust ordering patterns
-
Triage tools prioritize certain symptoms → Patients learn to emphasize those symptoms
-
Efficiency algorithms flag procedures → Documentation patterns shift to avoid flags
Gaube et al. found that while correct AI predictions improved diagnostic accuracy, incorrect predictions decreased physician accuracy below baseline.[7] Clinicians change behavior in response to AI, creating automation bias that propagates errors.
This is a socio-technical feedback system, not a static prediction problem. The prediction changes the distribution it was trained to predict.
[
{kind=link}
3. The Incentive Misalignment
Organizations pay for predictions, but what they need is outcomes. These often conflict.
Consider the principal-agent problems in most healthcare AI deployments.[8]
-
Hospital administrators seek cost reduction
-
Clinicians value professional autonomy
-
Patients want better outcomes
-
Payers want to minimize spending
-
AI developers optimize accuracy metrics
None of these naturally align. Deployment without explicit incentive design produces predictable failures:
-
AI that correctly identifies patients needing expensive interventions gets ignored when hospitals face cost penalties
-
Tools improving accuracy require workflow changes that reduce patients per hour
-
Systems catching billing errors save money for payers but create work for burdened providers
The venture capital pattern repeats: big funding for technically impressive AI, disappointing adoption rates, quiet pivots or shutdowns.
The Structural Opportunity in Different Markets
Here’s what makes the contrast instructive.
High-income market problem:
-
40 years of billing-optimized electronic health record data
-
Fee-for-service incentives embedded in every workflow
-
10-15 legacy systems per hospital requiring integration
-
Clinician tool fatigue after decades of “innovation”
LMIC (low- and middle-income country) structural advantage:
-
Digital infrastructure being built now with modern architecture
-
Mobile-first systems—leapfrog patterns similar to M-Pesa’s payment revolution
-
Outcome-focused incentives where resources are genuinely constrained
-
Clinicians seeking decision support, not experiencing overload
Kenya’s M-TIBA mobile health payment system achieved 80%+ clinic adoption by aligning incentives for patients (transparent pricing), providers (guaranteed payment), and funders (fraud reduction) from launch.[9] No billing codes. No prior authorization. Direct alignment from inception.
Yet global health receives a small fraction of healthcare AI investment, while the majority flows to markets with the most entrenched barriers.[10]
This represents not just an equity concern but a strategic opportunity.What DHEPlab Does
The Digital Health Economics & Policy Lab at UNC applies economic and behavioral science methods to digital health implementation. What unites our projects is understanding how digitization interacts with human behavior, institutional incentives, and health system design.
Causal Inference: Does an intervention change outcomes, or predict outcomes that would occur anyway? We use econometric methods—difference-in-differences, instrumental variables, regression discontinuity—to identify counterfactual impact. Not just “did accuracy improve?” but “did welfare improve, and for whom?”[11]
Measurement Economics: What are we actually measuring, and what biases does that embed? We study data provenance—how capacity constraints, reimbursement rules, and professional incentives shape what gets recorded.
Mechanism Design: How can incentive structures be redesigned so digital tools improve outcomes rather than optimize proxies? We draw on game theory and contract theory to create systems where stakeholders’ objectives align.[12]
Behavioral Science: How do clinicians, patients, and administrators actually respond to new digital tools? We study technology adoption, organizational change, and psychological factors that determine whether sophisticated systems get used or ignored.[13]
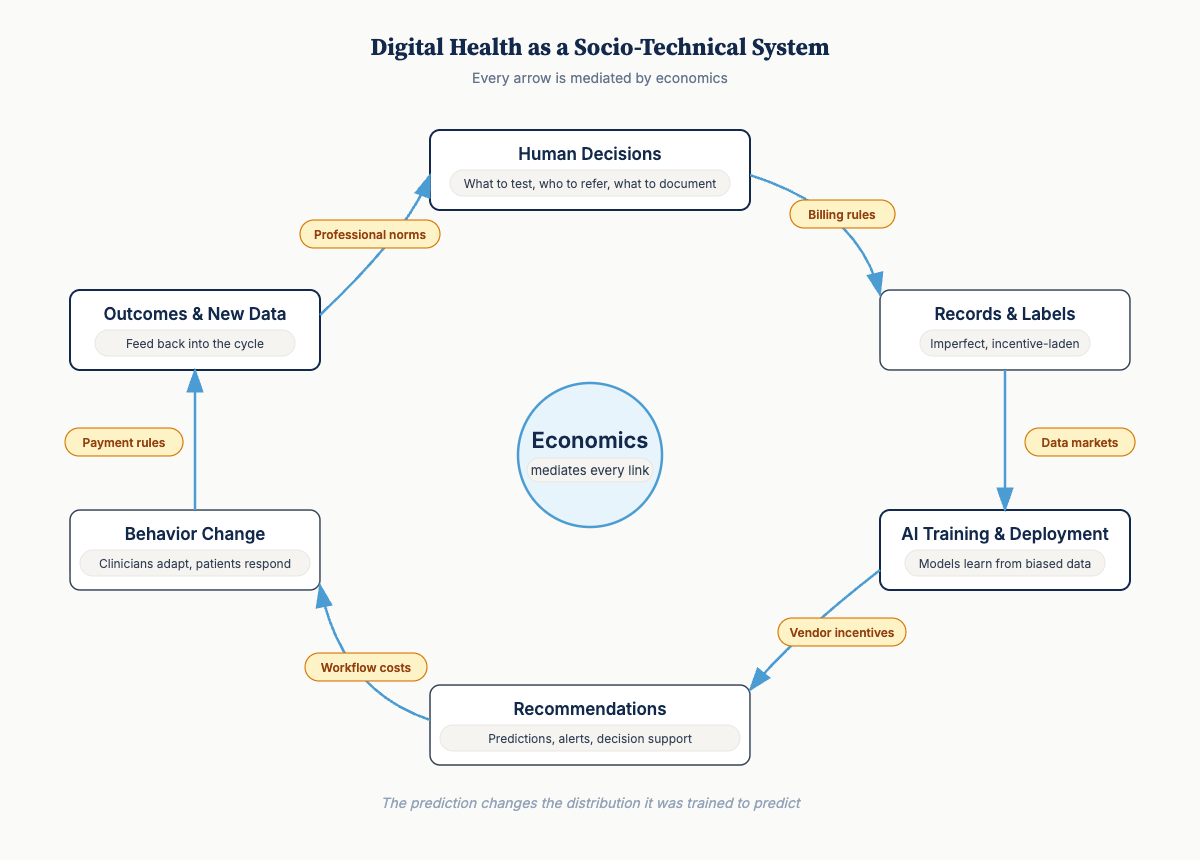
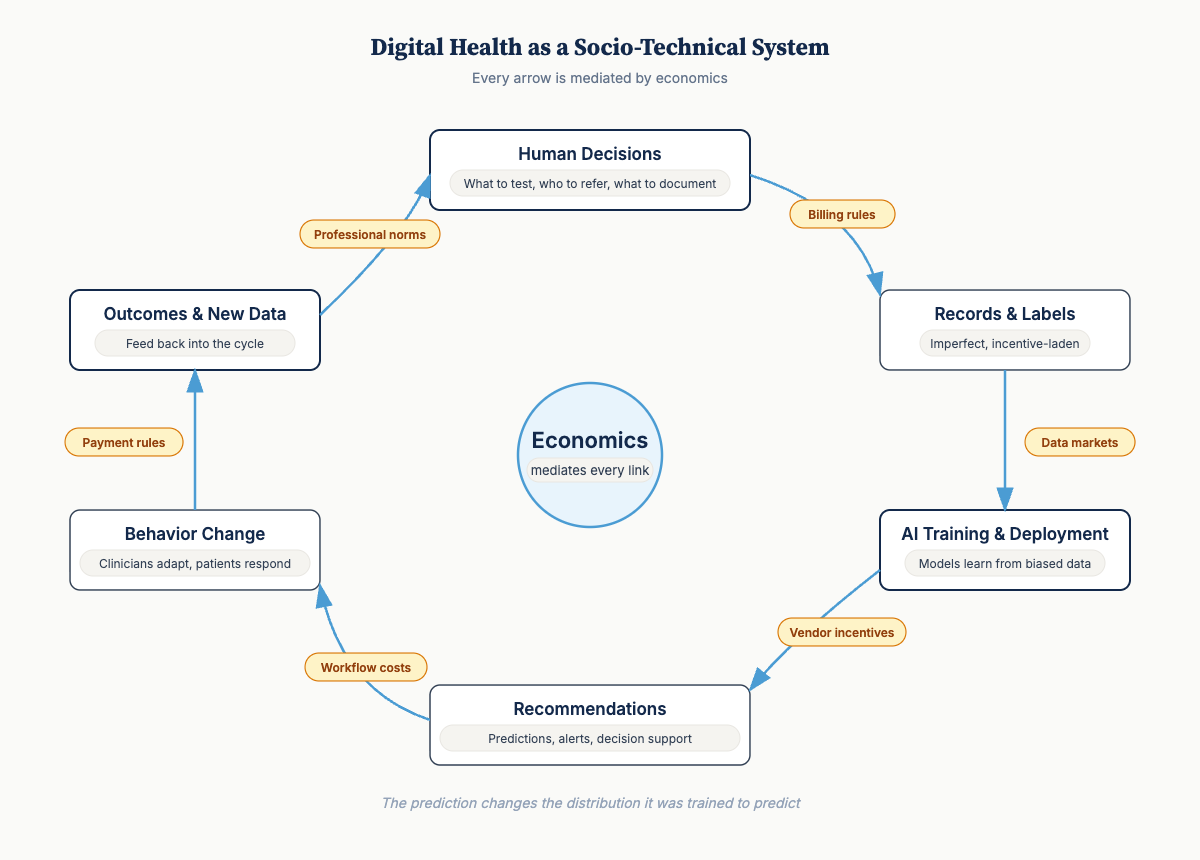
The Mental Model
Digital health as a socio-technical system:
Human decisions (what to test, who to refer, what to document) produce records and labels that are imperfect and incentive-laden → Those records feed AI training and deployment → Systems emit recommendations and information → These outputs shift downstream behavior, which produces outcomes and new data → The cycle continues.
Every arrow is mediated by economics—incentives, institutional rules, payment structures, professional norms, patient constraints.
What determines whether this loop improves outcomes or accelerates bias?
-
Measurement and causal identification to diagnose leverage points
-
Mechanism design to realign incentives toward better outcomes
-
Ongoing monitoring because systems evolve in response to digital tools
Most digital health projects do sophisticated technical work and assume the rest will sort itself out. Then they’re surprised when adoption fails.
What’s Coming
This newsletter shares frameworks, evidence, and insights for building digital health systems that work in the real world:
-
Coming next: The 52% Problem — A new Nature Medicine study found ChatGPT Health under-triages 52% of emergencies. We’ll show why this is exactly the failure mode the framework above predicts.
-
Decision-theoretic frameworks for digital health ROI — Why standard calculations mislead
-
Case studies from markets with different incentive structures — What M-TIBA and similar innovations teach us
-
Diagnostic frameworks for adoption barriers — Warning signs that incentives aren’t aligned
-
Research translations from causal inference, mechanism design, and behavioral economics
-
Methods deep-dives: Measuring causal impact of health AI, correcting selection bias
-
Global health spotlights: Innovation in resource-constrained settings
We’d love to hear from you!
What incentive misalignments have shaped your experience with health technology implementation? Do you have examples of promising technology meeting broken incentives or other behavioral roadblocks? Have you seen this as a challenge in your organization?
The Digital Health Economics & Policy Lab (DHEPlab) at UNC studies how digitization transforms healthcare systems, with particular focus on implementation barriers and LMIC contexts.
References:
-
Rock Health (2024). Digital Health Funding: 2024 Year in Review.
-
Sendak, M.P. et al. (2020). “A Path for Translation of Machine Learning Products into Healthcare Delivery.” EMJ Innovations. https://doi.org/10.33590/emjinnov/19-00172
-
Melnick, E.R. et al. (2020). “The Association Between Perceived Electronic Health Record Usability and Professional Burnout.” Mayo Clinic Proceedings. https://doi.org/10.1016/j.mayocp.2019.09.024
-
Muller, J.Z. (2018). The Tyranny of Metrics. Princeton University Press. ISBN: 9780691174952
-
Achoki, T. et al. (2019). “Health Disparities Across the Counties of Kenya.” Lancet Global Health. https://doi.org/10.1016/S2214-109X(18)30472-8
-
Obermeyer, Z. et al. (2019). “Dissecting Racial Bias in an Algorithm.” Science. https://doi.org/10.1126/science.aax2342
-
Gaube, S. et al. (2021). “Do as AI Say: Susceptibility in Deployment of Clinical Decision-Aids.” NPJ Digital Medicine. https://doi.org/10.1038/s41746-021-00385-9
-
Arrow, K. (1963). “Uncertainty and the Welfare Economics of Medical Care.” American Economic Review.
-
Ahmed, T. et al. (2022). “M-TIBA: A Digital Health Platform in Kenya.” BMJ Global Health. https://doi.org/10.1136/bmjgh-2021-007380
-
Lancet Digital Health Commission (2024). Global Digital Health.
-
Angrist, J.D. & Pischke, J.S. (2009). Mostly Harmless Econometrics. Princeton University Press.
-
Roth, A.E. (2015). Who Gets What—and Why. Houghton Mifflin Harcourt.
-
Damschroder, L.J. et al. (2009). “Fostering Implementation of Health Services Research Findings into Practice.” Implementation Science. https://doi.org/10.1186/1748-5908-4-50
Read on Substack
This post is also available on our Substack newsletter, where you can subscribe for updates.
View on Substack